云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么


Kisa_Artist2发布于 2026-02-17 01:43
云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
各位 M 站的老哥老铁们,好久不见!祝大家新年好!
祝大家在新的一年里:笔耕不辍有神作,身体倍棒不卡文,红红火火,万事如意!
最近过年闲着也是闲着,身为一个 Node.js 业余选手,我搞了个“无心之举”:写了个脚本去 小说 区转了一圈。本来只是想拉个词云看看大家最近都在写什么,结果代码跑着跑着,就捣鼓出一套叫 VDI(暴力密度指数) 的量化算法,还顺手拉了一张视觉冲击力挺强的词云图。
不过,目前的屏蔽词过滤逻辑还有点小缺陷,大家在图里可能会看到几个巨大的“漏网之鱼”。比如那几个日文名和特异名(没错,我说的就是占据了不小地盘的“早纪”和“鬣狗”),因为名字格式比较特殊,目前的黑名单没能完全拦住它们。这正说明了这几位作者最近的更新频率和热度实在是太高了,连算法都觉得它们是“核心关键词”。
由于我是测试,目前只跑了 前 7 页 的数据(大概 2000 多条回复)。虽然样本量还不算大,但已经能看出不少有意思的门道了

祝大家在新的一年里:笔耕不辍有神作,身体倍棒不卡文,红红火火,万事如意!
最近过年闲着也是闲着,身为一个 Node.js 业余选手,我搞了个“无心之举”:写了个脚本去 小说 区转了一圈。本来只是想拉个词云看看大家最近都在写什么,结果代码跑着跑着,就捣鼓出一套叫 VDI(暴力密度指数) 的量化算法,还顺手拉了一张视觉冲击力挺强的词云图。
不过,目前的屏蔽词过滤逻辑还有点小缺陷,大家在图里可能会看到几个巨大的“漏网之鱼”。比如那几个日文名和特异名(没错,我说的就是占据了不小地盘的“早纪”和“鬣狗”),因为名字格式比较特殊,目前的黑名单没能完全拦住它们。这正说明了这几位作者最近的更新频率和热度实在是太高了,连算法都觉得它们是“核心关键词”。
由于我是测试,目前只跑了 前 7 页 的数据(大概 2000 多条回复)。虽然样本量还不算大,但已经能看出不少有意思的门道了
Kisa_Artist2发布于 2026-02-17 01:50
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
什么是词云图?
词云图就是把一段文字里最重要的词挑出来,用大字显示;不那么重要的词用小字显示,然后拼成一张图。字越大,说明这个词在内容里越重要。
⚠️ 先说一句:这图仅供娱乐! 抓取范围和算法都有局限,结果可能不完全准,大家看着乐呵就行,别太当真。
数据从哪来?
抓取范围:
只抓 M站 N区的前 7 页
每页 30 个帖子,一共 210 个主题帖
每个帖子下面的回复也全部抓下来(大概 2000 多条)
⚠️ 注意:顶贴机制的影响
论坛有个"顶贴"规则:只要有新回复,帖子就会被顶到最前面。
这意味着:
抓到的 7 页是当前最活跃的帖子,不是最新的帖子
有些老帖子可能一直在被回复,所以长期霸占前排
有些新帖子可能没什么人回,就沉到后面没被抓到
所以词云图反映的是大家最近在聊什么,而不是最近发了什么
这张图是怎么做出来的?
第一步:洗数据
就像洗菜一样,先把"的"、"了"、"是"这些没有实际意义的词去掉。还要去掉人名(比如小说里的角色名),因为我们想看的是"内容主题"而不是"谁出现了"。
第二步:算重要性
不是简单地数哪个词出现次数多。而是用 TF-IDF 算法——既看这个词在这篇内容里出现了多少次,也看它在其他内容里是不是经常出现。如果一个词在这篇里很多,但在其他地方很少,那它就更重要。
第三步:分层摆放
想象你在一张纸上贴字:
大字(标题级):放在最中间,间距很宽,一眼就能看到
中字(段落级):填在大字周围的空隙里
小字(细节级):塞到边边角角,让图看起来更饱满
系统会一个一个试位置,如果两个字会重叠,就换个地方再试,直到找到合适的位置。
第四步:上色 + VDI 词库加成
金色词(核心关键词):这些词同时在 VDI 词库(我们整理的约 800 个敏感词库)和高频词里。金色表示这个词既是"大家爱聊的",又是"内容有强度的"。
彩色词(普通词):用各种鲜艳的颜色(红、蓝、绿、紫...),字越大颜色越实,字越小颜色越淡
VDI 词库在这里的作用: 它就像一个"筛子",帮我们找出那些真正代表内容特色的词。如果一个词在日常聊天里很常见(比如"喜欢"),但不在 VDI 词库里,那它再大也是普通的。但如果一个词既高频又在 VDI 词库里(比如"臣服"),那它就会变成金色,告诉你"这是这个区的特色内容"。
为什么这样设计?
因为人的眼睛看东西有习惯:先看中间,再看周围;先看大字,再看小字;先看金色,再看彩色。词云图就是利用这些习惯,让你一眼就能抓住内容的重点和特色。
词云图就是把一段文字里最重要的词挑出来,用大字显示;不那么重要的词用小字显示,然后拼成一张图。字越大,说明这个词在内容里越重要。
⚠️ 先说一句:这图仅供娱乐! 抓取范围和算法都有局限,结果可能不完全准,大家看着乐呵就行,别太当真。
数据从哪来?
抓取范围:
只抓 M站 N区的前 7 页
每页 30 个帖子,一共 210 个主题帖
每个帖子下面的回复也全部抓下来(大概 2000 多条)
⚠️ 注意:顶贴机制的影响
论坛有个"顶贴"规则:只要有新回复,帖子就会被顶到最前面。
这意味着:
抓到的 7 页是当前最活跃的帖子,不是最新的帖子
有些老帖子可能一直在被回复,所以长期霸占前排
有些新帖子可能没什么人回,就沉到后面没被抓到
所以词云图反映的是大家最近在聊什么,而不是最近发了什么
这张图是怎么做出来的?
第一步:洗数据
就像洗菜一样,先把"的"、"了"、"是"这些没有实际意义的词去掉。还要去掉人名(比如小说里的角色名),因为我们想看的是"内容主题"而不是"谁出现了"。
第二步:算重要性
不是简单地数哪个词出现次数多。而是用 TF-IDF 算法——既看这个词在这篇内容里出现了多少次,也看它在其他内容里是不是经常出现。如果一个词在这篇里很多,但在其他地方很少,那它就更重要。
第三步:分层摆放
想象你在一张纸上贴字:
大字(标题级):放在最中间,间距很宽,一眼就能看到
中字(段落级):填在大字周围的空隙里
小字(细节级):塞到边边角角,让图看起来更饱满
系统会一个一个试位置,如果两个字会重叠,就换个地方再试,直到找到合适的位置。
第四步:上色 + VDI 词库加成
金色词(核心关键词):这些词同时在 VDI 词库(我们整理的约 800 个敏感词库)和高频词里。金色表示这个词既是"大家爱聊的",又是"内容有强度的"。
彩色词(普通词):用各种鲜艳的颜色(红、蓝、绿、紫...),字越大颜色越实,字越小颜色越淡
VDI 词库在这里的作用: 它就像一个"筛子",帮我们找出那些真正代表内容特色的词。如果一个词在日常聊天里很常见(比如"喜欢"),但不在 VDI 词库里,那它再大也是普通的。但如果一个词既高频又在 VDI 词库里(比如"臣服"),那它就会变成金色,告诉你"这是这个区的特色内容"。
为什么这样设计?
因为人的眼睛看东西有习惯:先看中间,再看周围;先看大字,再看小字;先看金色,再看彩色。词云图就是利用这些习惯,让你一眼就能抓住内容的重点和特色。
Kisa_Artist2发布于 2026-02-17 01:52
Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Kisa_Artist2:↑什么是词云图?附录:VDI 是个啥?
词云图就是把一段文字里最重要的词挑出来,用大字显示;不那么重要的词用小字显示,然后拼成一张图。字越大,说明这个词在内容里越重要。
⚠️ 先说一句:这图仅供娱乐! 抓取范围和算法都有局限,结果可能不完全准,大家看着乐呵就行,别太当真。
数据从哪来?
抓取范围:
只抓 M站 N区的前 7 页
每页 30 个帖子,一共 210 个主题帖
每个帖子下面的回复也全部抓下来(大概 2000 多条)
⚠️ 注意:顶贴机制的影响
论坛有个"顶贴"规则:只要有新回复,帖子就会被顶到最前面。
这意味着:
抓到的 7 页是当前最活跃的帖子,不是最新的帖子
有些老帖子可能一直在被回复,所以长期霸占前排
有些新帖子可能没什么人回,就沉到后面没被抓到
所以词云图反映的是大家最近在聊什么,而不是最近发了什么
这张图是怎么做出来的?
第一步:洗数据
就像洗菜一样,先把"的"、"了"、"是"这些没有实际意义的词去掉。还要去掉人名(比如小说里的角色名),因为我们想看的是"内容主题"而不是"谁出现了"。
第二步:算重要性
不是简单地数哪个词出现次数多。而是用 TF-IDF 算法——既看这个词在这篇内容里出现了多少次,也看它在其他内容里是不是经常出现。如果一个词在这篇里很多,但在其他地方很少,那它就更重要。
第三步:分层摆放
想象你在一张纸上贴字:
大字(标题级):放在最中间,间距很宽,一眼就能看到
中字(段落级):填在大字周围的空隙里
小字(细节级):塞到边边角角,让图看起来更饱满
系统会一个一个试位置,如果两个字会重叠,就换个地方再试,直到找到合适的位置。
第四步:上色 + VDI 词库加成
金色词(核心关键词):这些词同时在 VDI 词库(我们整理的约 800 个敏感词库)和高频词里。金色表示这个词既是"大家爱聊的",又是"内容有强度的"。
彩色词(普通词):用各种鲜艳的颜色(红、蓝、绿、紫...),字越大颜色越实,字越小颜色越淡
VDI 词库在这里的作用: 它就像一个"筛子",帮我们找出那些真正代表内容特色的词。如果一个词在日常聊天里很常见(比如"喜欢"),但不在 VDI 词库里,那它再大也是普通的。但如果一个词既高频又在 VDI 词库里(比如"臣服"),那它就会变成金色,告诉你"这是这个区的特色内容"。
为什么这样设计?
因为人的眼睛看东西有习惯:先看中间,再看周围;先看大字,再看小字;先看金色,再看彩色。词云图就是利用这些习惯,让你一眼就能抓住内容的重点和特色。
VDI(暴力密度指数)是我们搞的一个"内容强度计",用来衡量一段文字里支配/臣服元素的浓度。
简单理解:
系统有一个"敏感词库",里面约 800 个词按强度分了 5 个等级
把文章分词后,一个词一个词检查,命中词库的就加分
最后算个平均分,看整篇文章是什么"强度"
词库是怎么构成的?
想象一个金字塔,从低到高:

加分机制: 如果一段文字里同时出现了多个层级的词(比如既有"命令"又有"羞辱"),VDI 会额外加分,因为"花样多"也是一种强度。
词库从哪来?
基础版:我们手动整理的 298 个核心词
扩展版:从网上动态加载的 500 多个词
可以热更新,不用重启就能加新词
等级划分(简化版):

注意: 详细的 VDI 分析(比如哪篇帖子最"重口"、整体分布图等)还在整理中,后面会发完整报告。这篇只是先放个词云图给大家看看~


vcrunyue考古专家发布于 2026-02-17 02:02
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
大佬牛逼,希望能持续更新,月更或者年更?
Kisa_Artist2发布于 2026-02-17 17:13
Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
vcruntimeyue:↑大佬牛逼,希望能持续更新,月更或者年更?谢谢!问得好!其实我一开始也想过按月更新,但是绕不开顶贴机制 所以无法准确生成当月的准确词云 现在只是做到了结合了顶贴的近期内容词云 我甚至设想过过按 thread 号增量抓取来实现。但深入分析后发现,大概有绕不开的难题:
1. 分区无法区分:论坛的 thread 号是全局递增的,所有分区的帖子共用同一个 ID 池。就算我知道 1 月份的 ID 范围(比如 10000~15000),这里面也混杂了水区、资源区、小说区等各种帖子。要只抓小说区,就必须把每个帖子的页面都打开,解析它属于哪个分区——这意味着要遍历几万个帖子,才能过滤出几百个小说区的帖子,性价比极低。
2服务器负载
所以,按月更新小说区词云,技术上几乎不可行,而且从服务器负载角度也不太合适——要么工作量巨大,要么数据不准,要么影响论坛正常运行。
而现在的方案(抓当前最活跃的帖子)虽然受顶贴机制影响,但至少能保证:
· 抓到的都是小说区的帖子(因为只从小说区列表页爬)
· 反映的是真实的“当前热门话题”
等有时间我可以开源 要是有技术能力的可以自己跑一跑看看最近的热门内容情况 也也可以用 OpenClaw 之类的工具自动化运行脚本,这样就能自己控制抓取时机而且运行更简单了
Kisa_Artist2发布于 ,编辑于 2026-02-18 00:21
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
我又跑了一次 更新了翻页机制 爬到了小说主题帖内的所有页面 但是部分新姓名又逃脱了过滤机制和我的过滤名单 有点影响观感 见谅 技术有限
这是报告
╔══════════════════════════════════════════════════════════╗
║ M站 N区 智能分析报告 v3.1 ║
╚══════════════════════════════════════════════════════════╝
📅 分析周期: 2026/2/10 ~ 2026/2/17
📊 数据概览: 210 个帖子 | 9481 条回复
🔤 分词引擎: nodejieba (专业分词)
╔══════════════════════════════════════════════════════════╗
║ 😊 情感分析 (基本) ║
╚══════════════════════════════════════════════════════════╝
正面情感: 34% (3226条)
负面情感: 11% (1016条)
中性情感: 55% (5239条)
正面关键词: 喜欢、爱、幸福、满足、兴奋、激动、渴望、服从、欣赏、享受
负面关键词: 痛苦、难受、折磨、挣扎、反抗、愤怒、恐惧、害怕、担心、尴尬
╔══════════════════════════════════════════════════════════╗
║ ⚡ 暴力密度指数 (VDI) 分析 ║
╚══════════════════════════════════════════════════════════╝
【整体 VDI 分布】
🟢 安全 (0-10): 52% (4884条)
🟡 轻度 (10-30): 25% (2404条)
🟠 中度 (30-60): 12% (1151条)
🔴 高度 (60-100): 4% (401条)
⚫ 极端 (100+): 4% (381条)
平均 VDI: 20.48 🟡 轻度
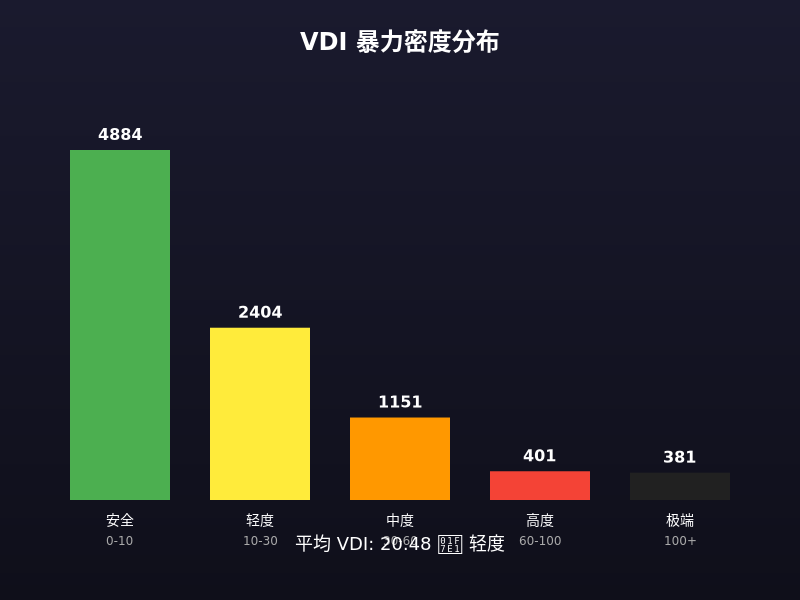
. 全贴平均 vs 局部高潮
目前的 VDI v3.1 采用的是全贴平均算法,而不是只抓取“楼主”或“高潮段落”。
受回复影响巨大:算法抓取的是整个主题帖下的所有回复(包括读者的催更、赞美、闲聊)。
“分母”稀释效应:如果一个帖子非常火,后面跟着几百楼的“好人一生平安”、“大大求更”,这些毫无强度的文字会极大地拉长文本总长度(L)。
结果:原本 90 分的高能片段,被 100 楼的闲聊稀释后,平均分可能直接掉到 20 分(🟠中度以下)。
2. “失真”现象说明
这就导致了部分优秀长篇作品的 VDI 指标严重偏低:
短篇优势:短篇小说回复少、干货占比高,VDI 容易爆表。
长篇劣势:越是人气高、互动多的长篇,平均分被摊得越薄。
⚠️ 特别说明:关于“全贴平均”导致的数值失真
关于某些长篇神作的 VDI 分数似乎偏低,或者一些新帖分数莫名很高,这主要是由于目前 VDI v3.1 采用的是**“全贴平均算法”**导致的:
3. 为什么“新帖/冷门帖”分数反而偏高?
样本纯度高:一些刚发的帖子或者没什么人回复的帖子,算法几乎只抓到了楼主的主体内容。
结果:没有了楼下“纯水回复”的稀释,这些帖子的 VDI 反而能维持在一个比较真实的、甚至偏高的位置。
这是报告
╔══════════════════════════════════════════════════════════╗
║ M站 N区 智能分析报告 v3.1 ║
╚══════════════════════════════════════════════════════════╝
📅 分析周期: 2026/2/10 ~ 2026/2/17
📊 数据概览: 210 个帖子 | 9481 条回复
🔤 分词引擎: nodejieba (专业分词)
╔══════════════════════════════════════════════════════════╗
║ 😊 情感分析 (基本) ║
╚══════════════════════════════════════════════════════════╝
正面情感: 34% (3226条)
负面情感: 11% (1016条)
中性情感: 55% (5239条)
正面关键词: 喜欢、爱、幸福、满足、兴奋、激动、渴望、服从、欣赏、享受
负面关键词: 痛苦、难受、折磨、挣扎、反抗、愤怒、恐惧、害怕、担心、尴尬
╔══════════════════════════════════════════════════════════╗
║ ⚡ 暴力密度指数 (VDI) 分析 ║
╚══════════════════════════════════════════════════════════╝
【整体 VDI 分布】
🟢 安全 (0-10): 52% (4884条)
🟡 轻度 (10-30): 25% (2404条)
🟠 中度 (30-60): 12% (1151条)
🔴 高度 (60-100): 4% (401条)
⚫ 极端 (100+): 4% (381条)
平均 VDI: 20.48 🟡 轻度
. 全贴平均 vs 局部高潮
目前的 VDI v3.1 采用的是全贴平均算法,而不是只抓取“楼主”或“高潮段落”。
受回复影响巨大:算法抓取的是整个主题帖下的所有回复(包括读者的催更、赞美、闲聊)。
“分母”稀释效应:如果一个帖子非常火,后面跟着几百楼的“好人一生平安”、“大大求更”,这些毫无强度的文字会极大地拉长文本总长度(L)。
结果:原本 90 分的高能片段,被 100 楼的闲聊稀释后,平均分可能直接掉到 20 分(🟠中度以下)。
2. “失真”现象说明
这就导致了部分优秀长篇作品的 VDI 指标严重偏低:
短篇优势:短篇小说回复少、干货占比高,VDI 容易爆表。
长篇劣势:越是人气高、互动多的长篇,平均分被摊得越薄。
⚠️ 特别说明:关于“全贴平均”导致的数值失真
关于某些长篇神作的 VDI 分数似乎偏低,或者一些新帖分数莫名很高,这主要是由于目前 VDI v3.1 采用的是**“全贴平均算法”**导致的:
3. 为什么“新帖/冷门帖”分数反而偏高?
样本纯度高:一些刚发的帖子或者没什么人回复的帖子,算法几乎只抓到了楼主的主体内容。
结果:没有了楼下“纯水回复”的稀释,这些帖子的 VDI 反而能维持在一个比较真实的、甚至偏高的位置。
Kisa_Artist2发布于 ,编辑于 2026-02-17 18:02
云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Kisa_Artist2:↑我又跑了一次 更新了翻页机制 爬到了小说主题帖内的所有页面 但是部分新姓名又逃脱了过滤机制和我的过滤名单 有点影响观感 见谅 技术有限【高频暴力词 TOP 10】
这是报告
╔══════════════════════════════════════════════════════════╗
║ M站 N区 智能分析报告 v3.0 ║
╚══════════════════════════════════════════════════════════╝
📅 分析周期: 2026/2/10 ~ 2026/2/17
📊 数据概览: 210 个帖子 | 9481 条回复
🔤 分词引擎: nodejieba (专业分词)
╔══════════════════════════════════════════════════════════╗
║ 😊 情感分析 (基本) ║
╚══════════════════════════════════════════════════════════╝
正面情感: 34% (3226条)
负面情感: 11% (1016条)
中性情感: 55% (5239条)
正面关键词: 喜欢、爱、幸福、满足、兴奋、激动、渴望、服从、欣赏、享受
负面关键词: 痛苦、难受、折磨、挣扎、反抗、愤怒、恐惧、害怕、担心、尴尬
╔══════════════════════════════════════════════════════════╗
║ ⚡ 暴力密度指数 (VDI) 分析 ║
╚══════════════════════════════════════════════════════════╝
【整体 VDI 分布】
🟢 安全 (0-10): 52% (4884条)
🟡 轻度 (10-30): 25% (2404条)
🟠 中度 (30-60): 12% (1151条)
🔴 高度 (60-100): 4% (401条)
⚫ 极端 (100+): 4% (381条)
平均 VDI: 20.48 🟡 轻度
🟠 中度 (30-60): 12% (1151条)
🔴 高度 (60-100): 4% (401条)
⚫ 极端 (100+): 4% (381条)
平均 VDI: 20.48 🟡 轻度
. 全贴平均 vs 局部高潮
目前的 VDI v3.1 采用的是全贴平均算法,而不是只抓取“楼主”或“高潮段落”。
受回复影响巨大:算法抓取的是整个主题帖下的所有回复(包括读者的催更、赞美、闲聊)。
“分母”稀释效应:如果一个帖子非常火,后面跟着几百楼的“好人一生平安”、“大大求更”,这些毫无强度的文字会极大地拉长文本总长度(L)。
结果:原本 90 分的高能片段,被 100 楼的闲聊稀释后,平均分可能直接掉到 20 分(🟠中度以下)。
2. “失真”现象说明
这就导致了部分优秀长篇作品的 VDI 指标严重偏低:
短篇优势:短篇小说回复少、干货占比高,VDI 容易爆表。
长篇劣势:越是人气高、互动多的长篇,平均分被摊得越薄。
⚠️ 特别说明:关于“全贴平均”导致的数值失真
很多老哥反馈某些长篇神作的 VDI 分数似乎偏低,或者一些新帖分数莫名很高,这主要是由于目前 VDI v3.1 采用的是**“全贴平均算法”**导致的:
3. 为什么“新帖/冷门帖”分数反而偏高?
样本纯度高:一些刚发的帖子或者没什么人回复的帖子,算法几乎只抓到了楼主的主体内容。
结果:没有了楼下“纯水回复”的稀释,这些帖子的 VDI 反而能维持在一个比较真实的、甚至偏高的位置。
排名 词汇 出现次数
────────────────────────
1. 踩 905次
2. 穿 889次
3. 折磨 563次
4. 踩踏 522次
5. 打 501次
6. 下 368次
7. 撕裂 351次
8. 喷射 315次
9. 射精 294次
10. 戳 285次
╔══════════════════════════════════════════════════════════╗
║ 👤 小说角色名 (已单独提取) 分词系统nr识别问题 ║
╚══════════════════════════════════════════════════════════╝
1. 颜心怜 3238次
2. 哈罗德 1942次
3. 小惠 1399次
4. 维尔 1354次
5. 直树 1319次
6. 莉娅 1309次
7. - 1187次
8. - 1164次
9. 瑪德琳 1091次
10. - 1072次
11. 小狗狗 1046次
12. 张晓静 1024次
13. 莉莉 980次
14. 王亚楠 971次
15. 林涛 950次
16.- 946次
17. - 915次
18. - 910次
19. - 908次
20. 由美江 885次
║ 👤 小说角色名 (提供之前2100回复版本)(设置了专门的文字黑名单过滤) 只扫描小说第一页 ║
╚══════════════════════════════════════════════════════════╝
1. 颜心怜 1020次
2. 聪美 992次
3. 王亚楠 848次
4. 浩明 803次
5. 莉娅 782次
6. 直树 718次
7. 江明玉 706次
8. 顾婉馨 648次
9. 李雪峰 548次
10. 徐雅倩 502次
11. 张晓静 469次
12. 林华 448次
13. 赵曦蕊 444次
14. 赵溪溪 440次
15. 爱丽丝 435次
16. 李婉宁 429次
17. 派拉莉丝 410次
18. 白杨 406次
19. 苏若晴 393次
📌 主题聚类 (基于共现网络) ║
╚══════════════════════════════════════════════════════════╝
【主题1】关于"肉棒"的讨论
关键词: 肉棒
热度: 🔥🔥🔥🔥🔥
【主题2】关于"主人"的讨论
关键词: 主人
热度: 🔥🔥🔥🔥🔥
【主题3】关于"艾卡"的讨论(没有过滤掉)
关键词: 艾卡
热度: 🔥🔥🔥🔥🔥
【主题3】关于"丝袜"的讨论 (结合之前的那一次计算)
关键词: 丝袜
热度: 🔥🔥🔥🔥🔥
【主题4】关于"少女"的讨论
关键词: 少女
热度: 🔥🔥🔥🔥🔥
【主题5】关于"快感"的讨论
关键词: 快感
热度: 🔥🔥🔥🔥🔥
║ 🔥 热词排行 (TF-IDF 加权 ║
╚══════════════════════════════════════════════════════════╝
排名 关键词 权重 频次 趋势
────────────────────────────────────────
1. 肉棒 43385.8 12903 🆕 +∞
2. 主人 25886.78 8297 🆕 +∞
3. 艾卡 22537.15 4007 🆕 +∞
4. 少女 19509.29 5455 🆕 +∞
5. 快感 18479.95 6163 🆕 +∞
6. 动作 16853.12 5890 🆕 +∞
7. 精液 16708.27 4853 🆕 +∞
8. 舌头 16195.23 5123 🆕 +∞
9. 丝袜 15832.1 4493 🆕 +∞
10. 眼神 15478.38 5467 🆕 +∞
11. 手指 14561.08 4967 🆕 +∞
12. 小涵 14477.8 2721 🆕 +∞
13. 双手 14050.92 4838 🆕 +∞
14. 眼睛 14040.45 5045 🆕 +∞
15. 抬起 13802.59 4841 🆕 +∞
16. 想要 13721.61 4897 🆕 +∞
17. 奴隶 13660.21 3620 🆕 +∞
18. 颤抖 13533.19 4568 🆕 +∞
19. 喜欢 13489.64 5210 🆕 +∞
20. 味道 13312.57 4330 🆕 +∞
21. 脚趾 13232.91 3730 🆕 +∞
22. 射精 13127.15 3703 🆕 +∞
23. 圣女 13109.55 2482 🆕 +∞
24. 露出 12882.25 4568 🆕 +∞
25. 用力 12640.68 4257 🆕 +∞
║ 🔗 词汇共现 (经常一起出现的词) ║
╚══════════════════════════════════════════════════════════╝
1. "眼睛" + "露出" ██████████ 1096
2. "眼睛" + "眼神" ██████████ 1094
3. "抬起" + "眼睛" ██████████ 1084
4. "抬起" + "眼神" ██████████ 1076
5. "动作" + "眼睛" ██████████ 1071
6. "想要" + "眼睛" ██████████ 1064
7. "眼神" + "露出" ██████████ 1060
8. "抬起" + "露出" ██████████ 1051
9. "动作" + "露出" ██████████ 1045
10. "动作" + "抬起" ██████████ 1043
11. "想要" + "露出" ██████████ 1037
12. "手指" + "眼睛" ██████████ 1030
13. "双手" + "眼睛" ██████████ 1028
14. "想要" + "抬起" ██████████ 1020
15. "双手" + "露出" ██████████ 1013
Kisa_Artist2发布于 ,编辑于 2026-02-17 17:34
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
╔══════════════════════════════════════════════════════════╗
║ 📝 内容长度分布(帖子统计 包含回复) ║
╚══════════════════════════════════════════════════════════╝
短篇(<50字): 4241 条
中篇(50-200字): 1744 条
长篇(200-500字): 877 条
超长(>500字): 2619 条
平均长度: 1728 字
══════════════════════════════════════════════════════════
智能分析系统 v3.1
功能: nodejieba + TF-IDF + 共现分析 + 情感分析 + 词云图
注意: 本报告仅供个人参考 技术有限 请见谅
║ 📝 内容长度分布(帖子统计 包含回复) ║
╚══════════════════════════════════════════════════════════╝
短篇(<50字): 4241 条
中篇(50-200字): 1744 条
长篇(200-500字): 877 条
超长(>500字): 2619 条
平均长度: 1728 字
══════════════════════════════════════════════════════════
智能分析系统 v3.1
功能: nodejieba + TF-IDF + 共现分析 + 情感分析 + 词云图
注意: 本报告仅供个人参考 技术有限 请见谅
Kisa_Artist2发布于 ,编辑于 2026-02-18 00:19
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
vdi-trend-replies-2026-02-17T08-36-36
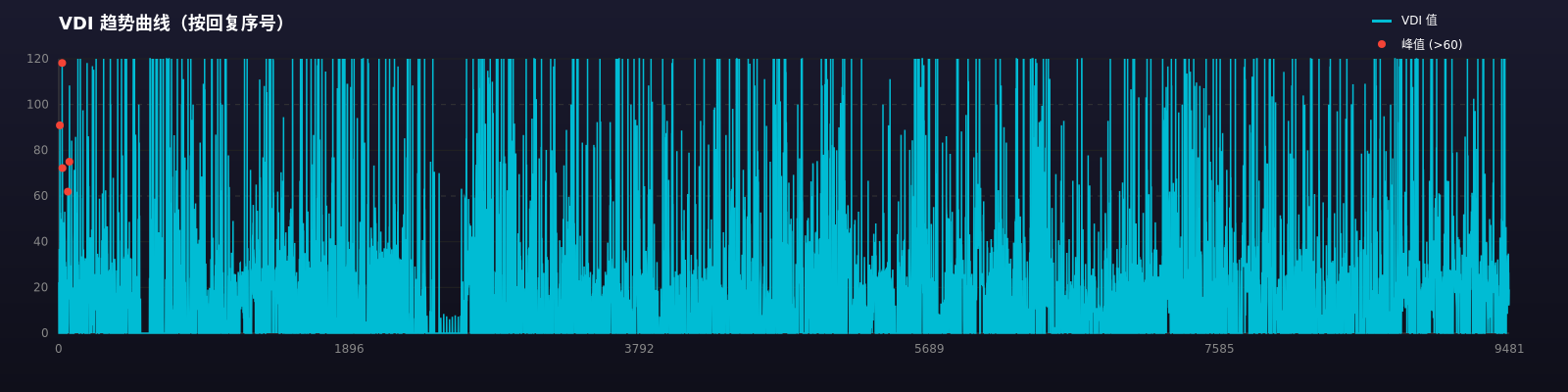
vdi-trend-threads-小说主题帖趋势 大概率受VDI平均计算偏低 新文收益更好 2026-02-17T08-36-36
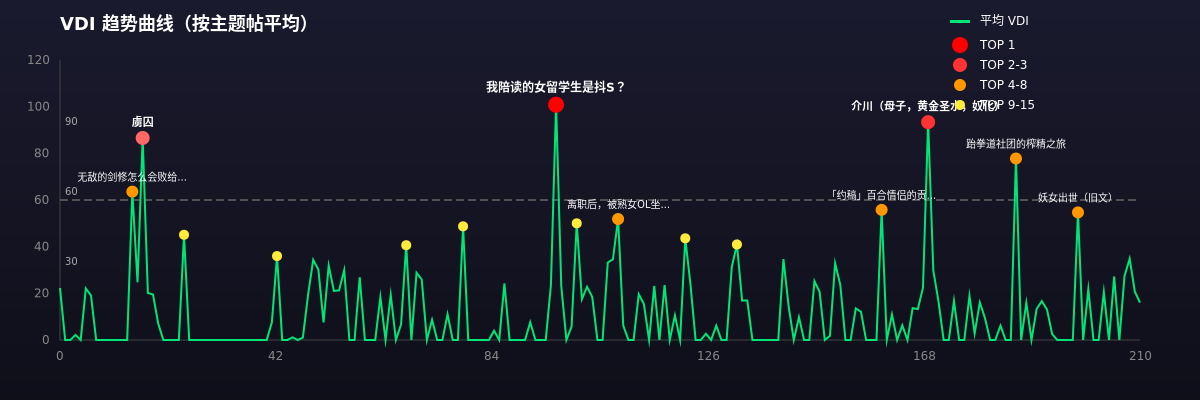
vdi-trend-threads-小说主题帖趋势 大概率受VDI平均计算偏低 新文收益更好 2026-02-17T08-36-36
Kisa_Artist2发布于 ,编辑于 2026-02-17 17:55
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
这是第一次的 只爬取了210篇小说的每篇第一页 某种程度可能也具有代表性
因为只抓第一页,它保留了作者最原始、最高能的描写浓度,所以 VDI 会高出很多。
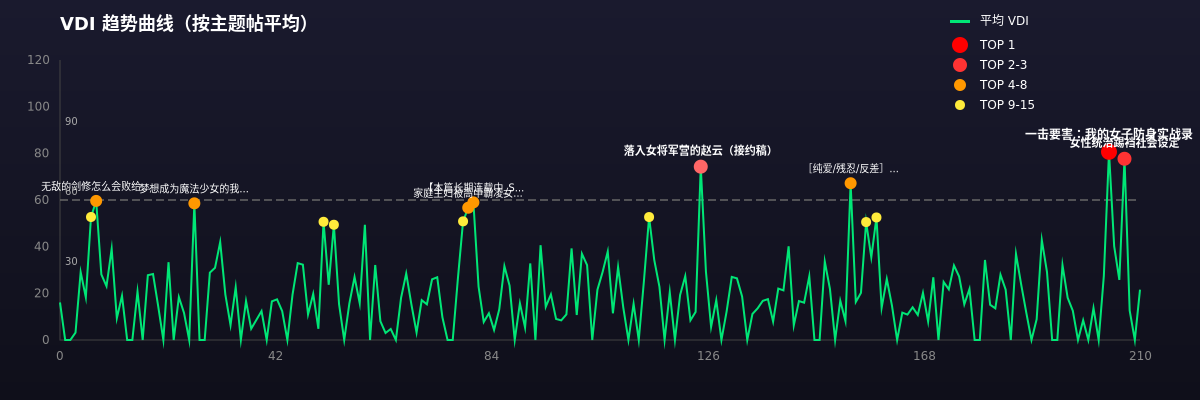
因为只抓第一页,它保留了作者最原始、最高能的描写浓度,所以 VDI 会高出很多。


Akane7发布于 2026-02-17 17:41
Re: Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Kisa_Artist2:↑7. 没想到 1187次这是?
8. 小心翼翼 1164次
Kisa_Artist2发布于 2026-02-17 17:44
Re: Re: Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Akane7:↑哈哈哈 bug 我剔除掉 😂Kisa_Artist2:↑7. 没想到 1187次这是?
8. 小心翼翼 1164次
Kisa_Artist2发布于 ,编辑于 2026-02-17 17:50
云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Akane7:↑😂 nodejieba 的词性分词不太准确 大家就当看个乐呵就行 没仔细审查Kisa_Artist2:↑7. 没想到 1187次这是?
8. 小心翼翼 1164次
vcrunyue考古专家发布于 2026-02-17 18:04
Re: Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
Kisa_Artist2:↑1这点倒是没想到,看来单独区分小说区可能不大可能了,只能手动。顶帖也是个麻烦,没法看最近一个月所有发布主题贴,手动也不行。话说这次云图分析里面,我应该贡献了大概3-5%的比例,约70条回复7w字左右,云图看到几个和我蛮相关的。vcruntimeyue:↑大佬牛逼,希望能持续更新,月更或者年更?谢谢!问得好!其实我一开始也想过按月更新,但是绕不开顶贴机制 所以无法准确生成当月的准确词云 现在只是做到了结合了顶贴的近期内容词云 我甚至设想过过按 thread 号增量抓取来实现。但深入分析后发现,大概有绕不开的难题:
1. 分区无法区分:论坛的 thread 号是全局递增的,所有分区的帖子共用同一个 ID 池。就算我知道 1 月份的 ID 范围(比如 10000~15000),这里面也混杂了水区、资源区、小说区等各种帖子。要只抓小说区,就必须把每个帖子的页面都打开,解析它属于哪个分区——这意味着要遍历几万个帖子,才能过滤出几百个小说区的帖子,性价比极低。
2服务器负载
所以,按月更新小说区词云,技术上几乎不可行,而且从服务器负载角度也不太合适——要么工作量巨大,要么数据不准,要么影响论坛正常运行。
而现在的方案(抓当前最活跃的帖子)虽然受顶贴机制影响,但至少能保证:
· 抓到的都是小说区的帖子(因为只从小说区列表页爬)
· 反映的是真实的“当前热门话题”
等有时间我可以开源 要是有技术能力的可以自己跑一跑看看最近的热门内容情况 也也可以用 OpenClaw 之类的工具自动化运行脚本,这样就能自己控制抓取时机而且运行更简单了


一名路人最佳读者发布于 2026-02-17 22:57
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
如果請站長來做統計是否會更好呢?畢竟他的權限應該是最高的,能有更好的數據與呈現方式?

Kisa_Artist2:↑如果一个词在这篇里很多,但在其他地方很少,那它就更重要。好像理解为什么图片里右边有鬣狗的词条了。有点离谱的词条。怎么说呢。第一眼想到了动物词条。非洲的鬣狗了。后来想起来了。是那篇文章。
vcrunyue考古专家发布于 2026-02-17 23:32
Re: Re: Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
ccxxyy:↑哪篇,突然好奇了Kisa_Artist2:↑如果一个词在这篇里很多,但在其他地方很少,那它就更重要。好像理解为什么图片里右边有鬣狗的词条了。有点离谱的词条。怎么说呢。第一眼想到了动物词条。非洲的鬣狗了。后来想起来了。是那篇文章。
Kisa_Artist2:↑我好像对小说区有一个想法。不过我建议你问问站长吧。这个对服务器负载太大了吧。vcruntimeyue:↑大佬牛逼,希望能持续更新,月更或者年更?谢谢!问得好!其实我一开始也想过按月更新,但是绕不开顶贴机制 所以无法准确生成当月的准确词云 现在只是做到了结合了顶贴的近期内容词云 我甚至设想过过按 thread 号增量抓取来实现。但深入分析后发现,大概有绕不开的难题:
1. 分区无法区分:论坛的 thread 号是全局递增的,所有分区的帖子共用同一个 ID 池。就算我知道 1 月份的 ID 范围(比如 10000~15000),这里面也混杂了水区、资源区、小说区等各种帖子。要只抓小说区,就必须把每个帖子的页面都打开,解析它属于哪个分区——这意味着要遍历几万个帖子,才能过滤出几百个小说区的帖子,性价比极低。
2服务器负载
所以,按月更新小说区词云,技术上几乎不可行,而且从服务器负载角度也不太合适——要么工作量巨大,要么数据不准,要么影响论坛正常运行。
而现在的方案(抓当前最活跃的帖子)虽然受顶贴机制影响,但至少能保证:
· 抓到的都是小说区的帖子(因为只从小说区列表页爬)
· 反映的是真实的“当前热门话题”
等有时间我可以开源 要是有技术能力的可以自己跑一跑看看最近的热门内容情况 也也可以用 OpenClaw 之类的工具自动化运行脚本,这样就能自己控制抓取时机而且运行更简单了
分区是按顺序继承的。要不要换个思路想法。因为小说区在网页上是/forum/18,通过网页先锁定,再进行搜集。好像对于脚本调试应该挺麻烦的。顶帖刷新重复之类的。还有别的问题。不过这样确实确保了都是小说区文章。

nebuchadnezzar血流成河发布于 2026-02-17 23:40
Re: 云图分析-数据不说谎:用 Node.js 爬了最近 2000 多条回复,带大家看小说区最近在写什么
数据可视化好啊
vcruntimeyue:↑不败战神的陨落,毒蜘蛛玩弄小鬣狗ccxxyy:↑哪篇,突然好奇了Kisa_Artist2:↑如果一个词在这篇里很多,但在其他地方很少,那它就更重要。好像理解为什么图片里右边有鬣狗的词条了。有点离谱的词条。怎么说呢。第一眼想到了动物词条。非洲的鬣狗了。后来想起来了。是那篇文章。